
Let's build a better Internet with a Free and Open cloud
Introduction
This post is about what motivates us to work on this project – our vision of a free and open cloud: what it is, how we can build it, and how it can help create a better Internet.
Practically every time you visit a website or use an app on your phone you are using services running in the cloud. We depend on them to communicate, to learn about the world, to get a job. We’ve come to accept that means entrusting our data and privacy with these opaque, proprietary services. And in turn the overwhelming majority of those services depend on just a handful of cloud providers. (In 2022, Amazon, Google, and Microsoft alone accounted for over 66% of the $217 billion cloud provider marketplace.)
What if we could build cloud applications that were transparent, democratically governed, and independent of the whims of corporations?
We’ve seen how open-source has transformed the way software is developed – open-source software today runs the critical infrastructure that powers our Internet, our servers, and most of our phones.
Imagine if cloud services and applications were freely available in the same way that open-source code is freely available – so users and developers can control the cloud they depend on.
TL;DR
This is a long post covering a lot of fairly abstract ground, so here’s an attempt at a summarizing its key points:
-
The open-source model that transformed software development – can we apply the same model to building a free and open cloud where live services are freely available just like code?
-
The fundamental difference between open-source code and a running cloud service is that the latter consumes resources like compute power and requires ongoing operational maintenance. So we need find a way to account for and settle those costs without compromising the freedoms provided by open-source. Happily, solving this problem also provides the opportunity to solve the biggest weakness of open source development model, namely how to sustainably fund its development.
-
We sketch out a decentralized architecture for a free and open cloud that can run on top of the hyper-scale cloud providers like AWS while providing mechanisms for sharing costs (autonomous services), fund support and maintenance (managed services), and funding open-source development (cloud-funding).
-
We can bootstrap this cloud from the vast ecosystem of open-source software that already exists today. First, create tools that make it easy to package, integrate and deploy open-source software on any cloud provider and make these “cloud blueprints” freely accessible, like a package manager for the cloud (we call this the “cloud map”). Second, build the core functionality of this free and open cloud: interoperable “public cloud providers” that run these cloud blueprints and enables the sharing of resources. Finally, as usage grows, the cloud-funding mechanism becomes economically viable to drive the development of open-source applications and services for our cloud.
-
Here at OneCommons we are building Unfurl and Unfurl Cloud to address the first technical challenges on this path – join us!
Contents
- Introduction
- TL;DR
- What We Mean by Free and Open
- The Free and Open Meta- Super- Distributed Multi-Cloud in the Sky
- How to Build a Free and Open Cloud
- Web3 and the Decentralized Free and Open Cloud
- The Free and Open Cloud is Already Here
- How to Get the Egg to the Other Side of the Road
- Conclusion and Getting Started
What We Mean by Free and Open
Imagine a cloud where:
- All applications and services are open-source
- You only pay for the raw compute resources consumed
- Services can run on any cloud provider or your own machines
- You have full control over your data
There’s FOSS – “free and open source software” – how about a free and open cloud?
If we start from the first principles of open-source what would a cloud that embodies the principles look like?
- Just like open source software, you have full access to the code that is needed to run the services running the cloud.
- Just like open source code, you are free to deploy and run those service yourself on your own infrastructure.
But running a cloud service involves hardware and electricity and ongoing maintenance and support – so how can it be free? We mean “free as in freedom, not as in free beer”, as open-source enthusiasts like to say.
In the context of the cloud, freedom means you’re not locked into any proprietary cloud provider – our vision is that compute power in the cloud should be a ubiquitous commodity like electricity. When you run an open-source service in a free and open cloud the only thing you should have to pay for is the compute resources you consume.
The Free and Open Meta- Super- Distributed Multi-Cloud in the Sky
While it is possible to build a cloud from scratch using open-source components like OpenStack or MAAS, pragmatically we don’t want to be limited to that. We want to be able to take advantage of the reach, familiarity, and efficiency of the major hyper-scale providers like AWS and Google Cloud as well as specialized providers like CDNs or GPU clouds. So any realistic approach to building a free and open cloud would need to work with existing cloud providers and seamlessly interoperate with proprietary cloud services.
We can take a small scale, bottoms-up, incremental approach to creating a free and open cloud by building one that can run on top of, and along-side, existing cloud infrastructure. Somewhat ironically, the buzz words that best describe this approach sound quite grandiose: the supercloud, the metacloud and Sky Computing.
All these concepts refer to an architectural layer above the hyper-scale cloud providers like AWS or Azure — with the goal to enable interoperability between clouds. A free and open cloud has the same goal because it isn’t tied to any one proprietary cloud platform.
So instead our free and open cloud is more of a meta-cloud that gives the user the freedom to run cloud services on any cloud provider or on their own hardware and easily migrate services across providers.
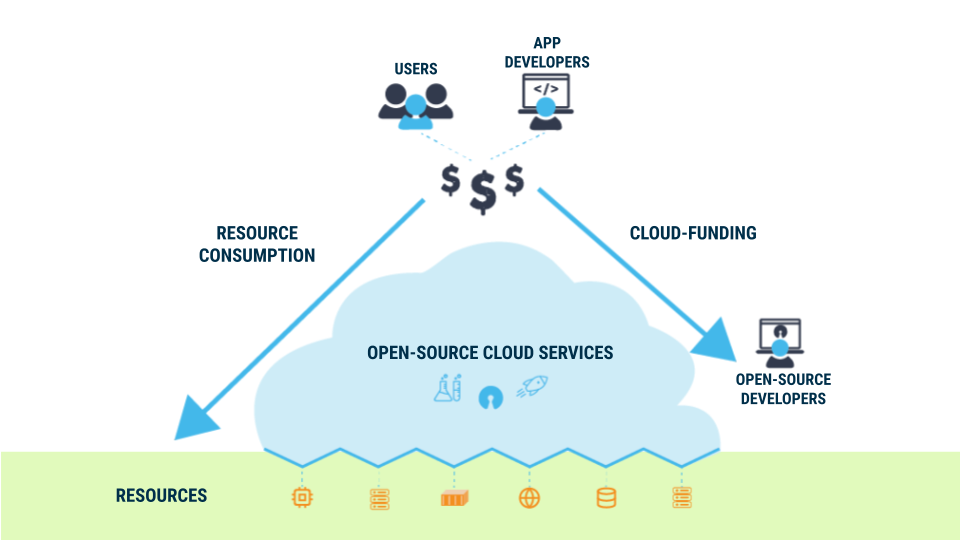
The above diagram shows a conceptual sketch of what a free and open cloud could look like.
At the bottom is the resource layer which defines the boundary of our open source cloud. It consists of the intrinsically non-free resources consumed by a service – such as compute power or data storage. A key for a cloud to remain free and open is to be able to treat those resources as interchangeable, fungible commodities. Then we can guarantee that all the code using those resources are open-source. We can think of the providers of these resources like a utilities company where users are only paying for the resources they consume.
Conceptually, the boundary between resources and open-source services is precisely where open-source ends and proprietary APIs begin. A resource might be anything from a high-level service such as a proprietary database to a low-level compute instance.
Above the resource layer are our cloud’s open-source services. Those services need to be made available so they can connected, provisioned, built from source, or deployed by anyone on using their own infrastructure.
And to be truly open and freely available we’ll need them available through a global, decentralized directory that anyone can access and contribute to.
At the top layer are the final consumers of these open cloud services: the applications that are utilizing these open cloud services or end-users that are connecting to them directly.
One important consequence of having a freely available service is that the user of the service or the provider of the resources it runs on must be able to run it themselves. Depending on the creator of the service (or any one particular entity for that matter) to provide the service contradicts the principle of a free and open service.
This implies that the users will need to directly pay for the resources that are consumed by the services they use. For services that are used by many users there will have to be a mechanism for determining a user’s share of the resources consumed. And as most services of any complexity will in turn rely on other services (for example, a database service) this usage tracking will need to span across downstream services.
The benefit for users is clear: they only pay for the resources they use. And for developers of these open-source cloud services and the software they depend on, these mechanisms open a door to create a sustainable model for funding open source development – we call that Cloud-funding. An ideal solution would be simple, equitable, and fair without undermining open-source ethics and motivations.
How to Build a Free and Open Cloud
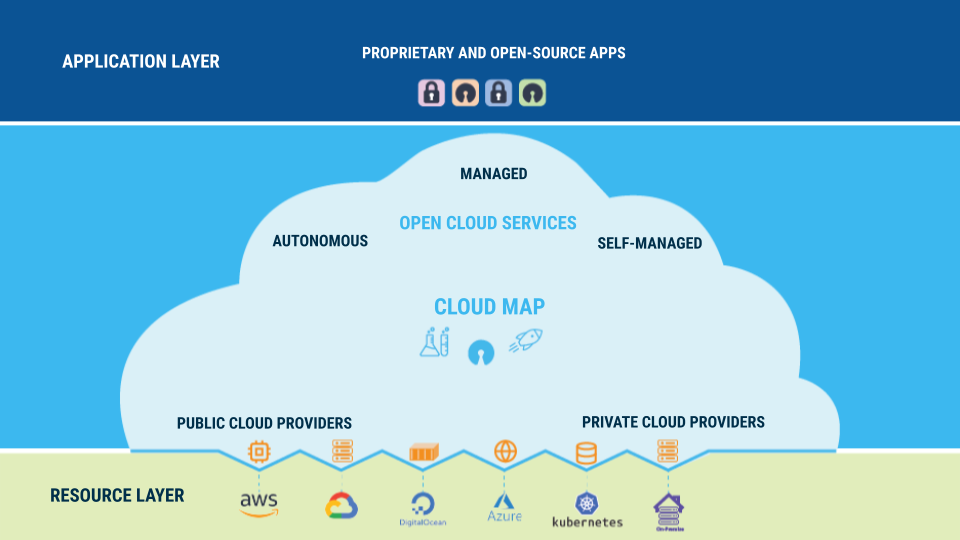
Now that we have a conceptual map of a free and open cloud, let’s drill into those layers and try to imagine what its ecosystem might look like. The architecture described below may be pie in the sky, head in the clouds (pun intended) but it is a useful thought experiment both to clarify the vision and to serve as a potential road map. And to help identify the parts of it that already exist.
Open Cloud Services
A free and open cloud can run any open-source software as long as the required resources are available – conceptually any cloud service can run in a free and open cloud as long as it is open-source.
An open cloud service doesn’t imply any architectural or API requirements – the only technical limitation is that the service works in an environment that tracks the resources its users consume. For example a service may be designed to run on a Kubernetes cluster or might be the Kubernetes cluster itself.
We can categorize open cloud services based on who runs and manages the service:
- Self-managed services are open cloud services deployed and privately managed by the user. This is the only type of cloud service available to private cloud providers.
- Autonomous services are services where access is shared by users. The cloud provider is responsible for managing access to it and providing support for the underlying resources it consumes. Volunteers may offer some management for a service but without any guarantees.
- Managed Services are open cloud services that are managed by a 3rd party, not by the user or the cloud provider. These would typically be commercial service providers that provide support and operational guarantees for a premium on top of the operational costs of running the service. Having the managed services open-source creates the conditions for a competitive marketplace of managed service providers with low barriers to entry.
Cloud Providers
The previous section talked about the resource layer that provides the resources that services consume – a cloud provider is the service that provides access to those resources and, as a consequence, hosts open cloud services. From the point of view of a developer or consumer of these services, a cloud provider is exposed as the APIs used to deploy or connect to open cloud services.
Clearly it would be hard to call a cloud free and open if it depended on some centralized authority to provide access to resources – so it will need an open ecosystem of independent cloud providers. As with open cloud services, we can categorize cloud providers by who runs them:
Private Cloud Providers
Private cloud providers are run by the users deploying self-managed services. It can be as simple as a light-weight, read-only implementation that is a thin layer that manages the user’s accounts on an existing commercial cloud provider such as Amazon AWS. A private cloud provider doesn’t need to run independently – it can be as simple as a client-side library that acts a facade around an existing cloud provider’s APIs.
Public Cloud Providers
Public cloud providers are run by a 3rd party such as a commercial service. Users establish accounts with public cloud providers and pay for resource consumption through them. Since these providers supports many users, they can run autonomous services and manage the connections to them so their costs are equitably shared. The same mechanisms can be used to provide access to managed services, much like how today’s large commercial cloud providers have marketplaces for 3rd party services. Similarly, these mechanisms enable Cloud-funding.
A public cloud providers need not be a full hosting service that manages its own compute resources or data centers – instead it might be a service that provides a management layer on top of existing cloud providers, as many PaaS (platform-as-a-service) services do today.
The Cloud Map
We need a way to access available open cloud services that is independent of individual cloud providers and, ideally, any centralized authority. This can be achieved by something as simple as a public git repository that can be mirrored or forked.
Let’s call this a cloudmap. A cloud map is a catalog of open cloud services that describes how to build and deploy those services from source code. It should also describe the dependencies between services and lists service instances publicly available on cloud providers. Cloud providers can rely on this cloud map as the source of their open cloud services and contribute to it by publishing the services they support.
Web3 and the Decentralized Free and Open Cloud
A free and open cloud shares many of the same goals and aspirations as the wider Web3 ecosystem and clearly it will need to adopt Web3 technology (decentralized identity, data, etc.) to achieve Internet scale. And indeed, the CloudMap described above is essentially a decentralized data store.
A free and open cloud solves some key missing pieces of the Web3 puzzle:
Fundamentally, Web3 technology decentralizes applications, allowing the user to retain control and ownership of their data. But there are some applications and functionality that very difficult to decentralize.
There are always going to be components that require significant centralized computing power (e.g. search, many kinds of AI, “big data”) and there are always going to be services that users don’t want to or cannot run on their own.
A free and open cloud provides a way for those functions that can’t easily be decentralized to at least be managed in a decentralized manner if they are implemented as freely available open cloud services.
Beyond that, Web3 applications require a whole new technology stack to be built. Even after Web3 exists there will still be thousands of web applications and millions of lines of code that would have to be re-written. But a free and open cloud can work with existing architectures and technology, providing a pragmatic approach to unlocking much of the promise of Web3 today without having to re-invent everything.
The Free and Open Cloud is Already Here
Sounds pretty utopian – and it is! (in a good way). But within the expansive universe of open-source software most of the pieces are already here, we just need to connect the dots.
From high-level user-facing web applications like WordPress or odoo down to low-level services for managing of hardware like MAAS or OpenSwitch to all the databases, servers, Cloud Native middleware in between – there are enough open-source solutions to create a free and open cloud if we can create the right tools to easily and robustly integrate these components together.
So let’s start with useful, practical tools that meet these technical requirements:
-
If we want services and infrastructure that anyone can clone and deploy from source code we need to enable transparent, automated, and secure deployment from code.
-
If we want services that can run anywhere we need technology that is based on open standards and cloud-provider independent.
To meet these requirements we’ve built Unfurl, a deployment engine, and Unfurl Cloud, a development platform for building our free and open cloud.
Unfurl
Unfurl is a command-line tool for deploying and managing cloud services. It manages Git repositories so live services can be mapped back to a reproducible deployment process grounded by code. The ultimate goal of Unfurl is to enable anyone to clone, fork, and deploy live cloud services as easily as cloning and building code from git.
Unfurl implements OASIS TOSCA (Topology and Orchestration Specification for Cloud Applications), a standard that enables cloud-provider independent abstractions of cloud infrastructure and services. We choose TOSCA because it is the only general purpose open standard for describing and orchestrating deployments.
Unfurl as a Private Cloud Provider
You can use Unfurl as a private cloud provider as described in the previous section. It works with a CloudMap to discover and deploy cloud blueprints and open cloud services – much like a package manager that installs software packages.
Unfurl manages connections to a user’s cloud accounts and cloud independence though our TOSCA types library, which provides high-level abstractions for common cloud concepts, such as compute instances and SQL databases. Using Unfurl types, the same blueprint can be deployed in a wide range of configurations, from simple and cheap compute instances to Kubernetes clusters.
Unfurl Cloud
Unfurl Cloud is a platform (open-source of course!) for building our free and open cloud, and the beginnings of a “public cloud provider” as described in the previous section.
As a deployment platform, Unfurl Cloud hosts your Unfurl projects, providing a simple user interface for deploying onto your own cloud accounts. You can deploy from its catalog of pre-defined cloud blueprints or deploy from code using Unfurl Cloud’s code pipelines and container registries.
Unfurl Cloud supports the development of reproducible cloud services through the ubiquitous use of git throughout a service’s development life-cycle – from code to configuration to operations. For example, edits in our user-interfaces are committed to git as user-editable YAML.
Unfurl Cloud as a Public Cloud Provider
As a public cloud provider, you can deploy services onto our public cloud and make them publicly available to any developer. You can also connect to open cloud services that are published on Unfurl Cloud. We’ve implemented “testbed” projects where teams can collaboratively deploy and manage cloud services and publish services as API in our public cloud.
Unfurl Cloud generates a CloudMap of all the publicly available services and cloud blueprints it hosts – seeding a free and open cloud and making it easy to discover, clone, and deploy services without any dependency on Unfurl Cloud.
How to Get the Egg to the Other Side of the Road
Building open-source cloud solutions is certainly valuable and useful but there is a “phase change” where a free and open cloud creates something fundamentally different from cloud computing today: that point where our cloud “comes alive” – that is, reaches a critical mass of compute resources and autonomous open cloud services so its core functionality and infrastructure achieves a permanence even as individual participants come and go.
While getting to that point may look like a classic chicken or egg dilemma for collective action it can be bootstrapped in the same way successful grassroots open-source projects have grown:
First, just like any good open source project: provide free, useful tools that provides immediate benefits. A tool that makes it easy to deploy and manage open source software so developers can reduce costs, avoid vendor lock-in, and enable flexibility and control.
Second, make it easy for users to use those tools to contribute their deployments, configurations, and cloud blueprints back to the cloud map and make it easy for developers to collaborate and support each other.
Third, when there is a critical mass of blueprints and developers, that creates enough of a market to incentive cloud providers and managed service providers to participate. At this point the cloud’s open-source nature and open APIs create a new dynamo for growth by enabling a market with low barriers to entry and a level playing field. By increasing competition and reducing lock-in, we create a virtuous circle that reduces costs and increases the diversity of solutions.
Finally, when our cloud reaches a large enough scale, its cloud-funding mechanism will provide enough funding to directly sustain the open-source projects that open cloud services depend on – creating a new sustainable business model for open-source development.
There’s an old Internet joke: “we lose money on every sale, but make it up in volume.” Underpinning that joke is the reality that in the cloud, at scale the marginal costs for a transaction tends towards zero. If you manage to reach that scale you can have an extremely profitable business. This is one fundamental reason why the network externalities of the Internet leads to monopolistic positions and Big Tech dominates.
But in a free and open cloud everyone benefits from that scale, not just the gate-keepers. Efficiencies are shared and anyone can build applications that leverage a huge ecosystem of open-source services while only paying per-transaction costs (which in turn can fund that open-source innovation).
Conclusion and Getting Started
If we look at upcoming digital technologies poised to make the biggest impact on our lives – such as AI, big data, VR, even Web3 and block chain – they will all be manifested and made available as cloud-based applications and services. Who will control them? Who will benefit from them? If we can build a free and open cloud – essentially open, shared, re-usable cloud infrastructure – that lays the groundwork for creating cloud applications as public goods, governed by its developers and users.
As ambitious as this may sound, we can build this from the bottoms up without having to bet on any technical breakthroughs or speculative new technologies. The ideas in this post are just that – a collection of ideas that have evolved and coalesced together as we’ve built Unfurl and Unfurl Cloud. I don’t believe there needs to be an over-arching project or dedicated organization to start making this a reality, just having these ideas and goals inform the open-source tools we build is enough.
To use Unfurl and Unfurl Cloud as an example: we’re focused on making it easy for individual developers or small teams to integrate and deploy open source services and applications. As the cloudmap idea evolved, we’ve steered our design around that concept to make it easy for users to share those integrations in a cloudmap.
Whether you are an open-source enthusiast or a hard-core developer, there are many different ways you can help make this vision become a reality – here are some:
- Build cloud blueprints using Unfurl.
- Help build the cloudmap – any public cloud blueprints hosted on unfurl.cloud are automatically synced – or just submit a pull request.
- Deploy open-source applications with cloud blueprints. Unfurl Cloud provides a simple UI for deploying to a range of destinations from low-cost machines to Kubernetes clusters while handling tedious tasks like setting up DNS and provisioning HTTPS certificates.
- Contribute to our core open-source projects: unfurl, unfurl cloud, and unfurl types.
- Tell us what you think or just send signals to the world that you think this is cool: create an account on Unfurl Cloud, join our Discord, star us on Github.